MongoDB data modeling
1 Use case scenario
We consider a relational database that holds the data of a chain of DVD stores; the database name is Sakila.
The Sakila database is serving an increasing number of queries from staff and customers around the world. A single monolithic database is not sufficient anymore to serve all the requests and the company is thinking about distributing the database across several servers (horizontal scalability). However, a relational database does not handle horizontal scalability very well, due to the fact that the data is scattered across numerous tables, as the result of the normalization process. Hence, the Sakila team is turning to you to help them migrate the database from PostgreSQL to MongoDB.
For the migration to happen, it is necessary to conceive a suitable data model. From the first discussions with the Sakila management, you quickly understand that one of the main use of the database is to manage (add, update and read) rental information.
1.1 Description of the relational model
The existing data model is recalled in Figure 1.1.
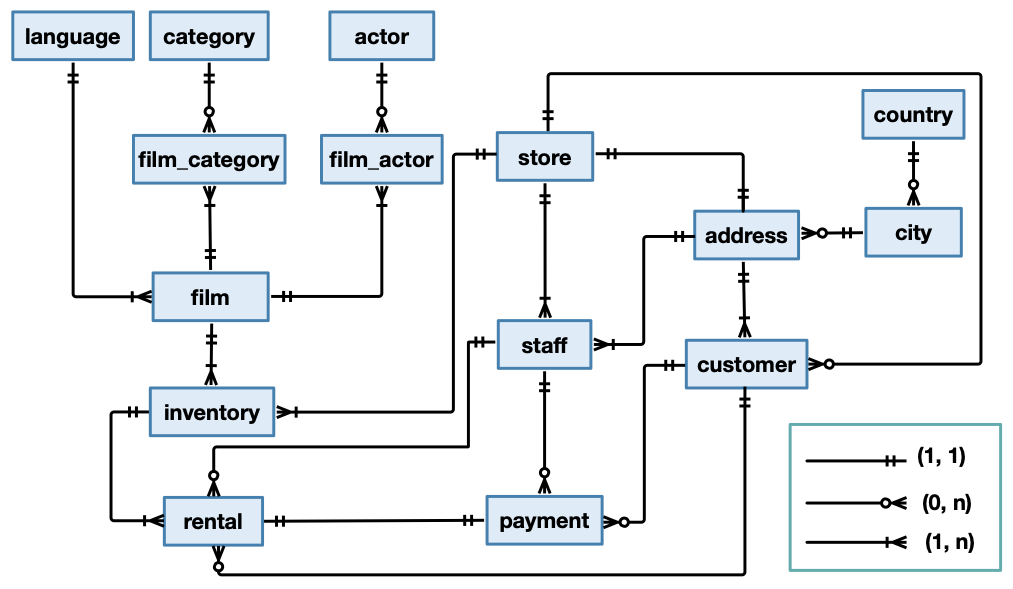
Figure 1.1: The logical schema of the Sakila database
Here is the description of the tables:
The table actor lists information for all actors. Columns: actor_id, first_name, last_name.
The table address contains address information for customers, staff and stores. Columns: address_id, address, address2, district, city_id, postal_code, phone.
The table category lists the categories that can be assigned to a film. Columns: category_id, name.
The table city contains a list of cities. Columns: city_id, city, country_id.
The table country contains a list of countries. Columns: country_id, country.
The table customer contains a list of all customers. Columns: customer_id, store_id, first_name, last_name, email, address_id, active, create_date.
The table film is a list of all films potentially in stock in the stores. The actual in-stock copies of each film are represented in the inventory table. Columns: film_id, title, description, release_year, language_id, original_language_id, rental_duration, rental_rate, length.
The table film_actor is used to support a many-to-many relationship between films and actors. Columns: film_id, actor_id.
The table film_category is used to support a many-to-many relationship between films and categories. Columns: film_id, category_id.
The table inventory contains one row for each copy of a given film in a given store. Columns: inventory_id, film_id, store_id.
The table language contains possible languages that films can have for their language and original language values. Columns: language_id, name.
The table payment records each payment made by a customer, with information such as the amount and the rental being paid for. Columns: payment_id, customer_id, staff_id, rental_id, amount, payment_date.
The table rental contains one row for each rental of each inventory item with information about who rented what item, when it was rented, and when it was returned. Columns: rental_id, rental_date, inventory_id, customer_id, return_date, staff_id.
The table staff lists all staff members. Columns: staff_id, first_name, last_name, address_id, picture, email, store_id, active, username, password.
The table store lists all stores in the system. Columns: store_id, manager_staff_id, address_id.
2 Data types in MongDB
A MongoDB document is represented as a JSON record. However, internally MongoDB serializes the JSON record into a BSON record. In practice, a BSON record is a binary representation of a JSON record.
Exercise
Exercise 2.1 Looking at the specification of BSON, can you tell how many bytes do you need to represent: an integer, a date, a string and a boolean?
Exercise
Exercise 2.2 The size of a document in MongoDB is limited to 16 MiB. Can you tell why there is such a limit?
The table rental has four integer columns (rental_id, inventory_id, customer_id, staff_id) and 2 dates (rental_date, return_date).
The table customer has three integer columns (customer_id, store_id, address_id), three strings (first_name, last_name and email), one boolean value (active) and one date (create_date).
Exercise
Exercise 2.3 Suppose that we want to create a MongoDB collection to list all rentals, and a separate collection to list all customers.
Estimate the size of a document in both collections.
We make the following assumptions:
On average, each character needs 1.5 bytes.
An email address is 20 characters long on average.
A last name is 8 characters long on average.
- A first name is 6 characters long on average.
3 Considerations for the new model
Denormalization in MongoDB is strongly encouraged to read and write a record relative to an entity in one single operation.
In the following exercises, we explore different options and analyze advantages and disadvantages.
Exercise
Exercise 3.1 Suppose that we create a collection Customer, where each document includes information about a customer.
Suppose that we embed in each document the list of rentals for a customer.
How many rentals can we store for a given customer, knowing that the size of a document in MongoDB cannot exceed 16 MiB?
Exercise
Exercise 3.2 Consider the two following options:
A collection customer, where each document contains the information about a customer and an embedded list with the information on all the rentals made by the customer. We assume that the average number of rentals per customer is 32.
A collection rental, where each document contains the information about a rental and an embedded document with the information on the customer that made the rental.
Compute the size in byte of a document in the two collections.
Exercise
Exercise 3.3 Suppose that we have in our database
512 customers.
16384 rentals.
On average, each customer has around 32 rentals.
Compute the size in byte of the collections customer and rental described in the previous question.
Exercise
Exercise 3.4 Based on the answers in the previous questions, discuss advantages and disadvantages of the two options: having a collection customer (solution 1) or a collection rental (solution 2).
Exercise
Exercise 3.5 Look again at the model in Figure 1.1. A rental document doesn’t only need to include information on the customer who made the rental, but also:
The staff member who took care of the rental.
The inventory item being rented.
The payment information.
Questions.
Discuss the different ways we can include this information in the collections customer and rental.
Based on the discussion, which solution would you retain? A collection customer or a collection rental?
4 The data model in MongoDB
In the last question, we chose the collection that we intend to create.
Exercise
Exercise 4.1 Give the complete schema (name and type of the properties) of a document in the collection that you chose in the previous question.
If the value of any property is an embedded document:
Specify the schema of that document too.
If any property of an embedded document is an identifier referencing another entity, use that identifier (don’t try, for now, to further denormalize the schema).
Let’s take a closer look at the storage requirements of the adopted solution. Consider that:
The size in bytes of a document storing the information of a staff member is around 64 KiB (65,536 bytes), because we store a profile picture.
The size in bytes of a document storing the information of an inventory item is 12 bytes.
The size in bytes of a document storing the information about a payment is 20 bytes.
Exercise
Exercise 4.2 If we denote by \(N_{rental}\) the number of rentals, what is the size in bytes of the database for the adopted solution? What do you get if we set \(N_{rental}\) to \(10^4\), \(10^5\) or \(10^6\) ?
Although the size that we determined in the previous exercise, may not sound impressive, we still have to store other information (films, actors….). If we could save a bit of space, we would be happy.
Exercise
Exercise 4.3 Discuss how you could save some space in the adopted solution.
HINT. Do you really need to denormalize all data?
Exercise
Exercise 4.4 Propose a solution for all the entities involved and estimate the savings in terms of storage requirements.
5 The new model
In this section we intend to obtain a complete model of the Sakila database.
Exercise
Exercise 5.1 Consider the model that we obtained at the end of the previous section. Which data can you further denormalize?
Exercise
Exercise 5.2 Complete the diagram obtained in the previous exercise so as to obtain a full data model for the Sakila database.