Data warehousing
In this tutorial you will learn basic modeling strategies for a data warehouse.
Use case scenario
We intend to set up a data warehouse for the Sakila database that we used in Tutorial 3.
We suppose that a DVD rental store chain (let’s call it Sakila) maintains several operational database systems at their different stores, and the management intends to have a single point of truth, in order to check business trends. Hence, the idea of setting up a data warehouse.
In order to model a schema for the Sakila data warehouse, we need to identify dimensions and facts. To this extent, we first identify the business questions that the Sakila management wants to be answered.
Exercise
Exercise 1 List some of the business questions that the Sakila management would like to answer.
Solution
Different sets of questions are possible. Here are some examples.
- Which store generates the most revenue?
- Which customers have rented the most in the past year? (maybe to award fidelity points).
- Which customers have rented the least in the past year? (maybe to offer some discounts to encourage the customer to rent again).
- Which staffer has processed the most of the rentals in the past year? (staffer of the year).
- Which staffer has processed the least of the rentals in the past year? (maybe a layoff in sight?).
- Which month has the highest revenue? By country, by store?
- Which country generates the least revenue? (is there any concurrent out there that might be soon a threat in other countries too?)
- Which categories of films are most popular?
We recall here the conceptual model of the Sakila database.
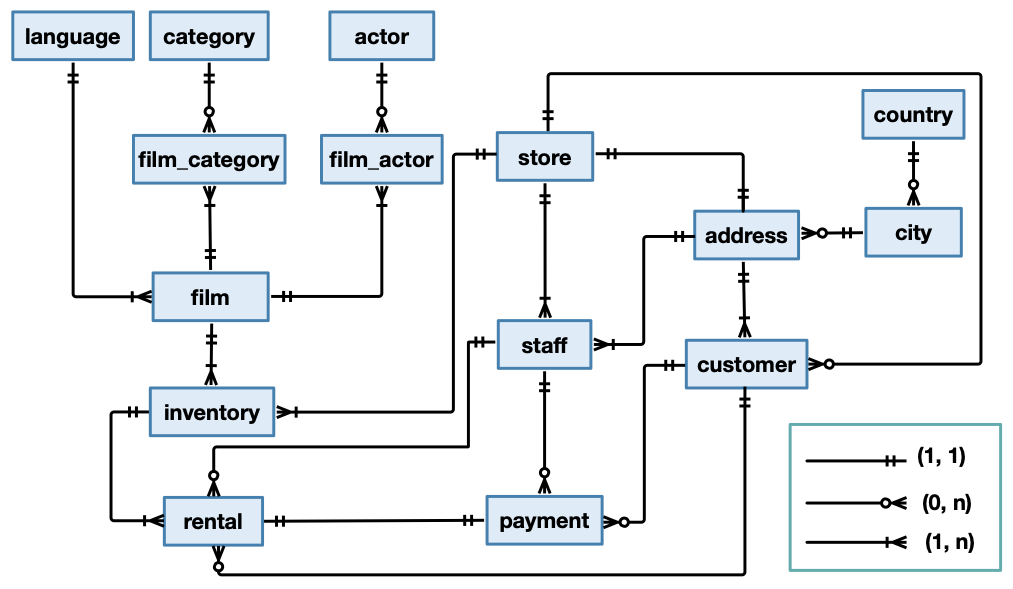
Figure 1: The conceptual schema of the Sakila database
Exercise
Exercise 2 Based on the business questions identified in the first exercise, can you tell what the fact and the dimension tables are?
Recall that the fact table should contain measures and the dimension tables should contain the context of the facts. The dimension table should answer the following questions about a fact: who, what, when, where.
Solution
From the questions that we identified in the previous exercise, it is clear that we intend to use the data warehouse to answer questions about the rentals.
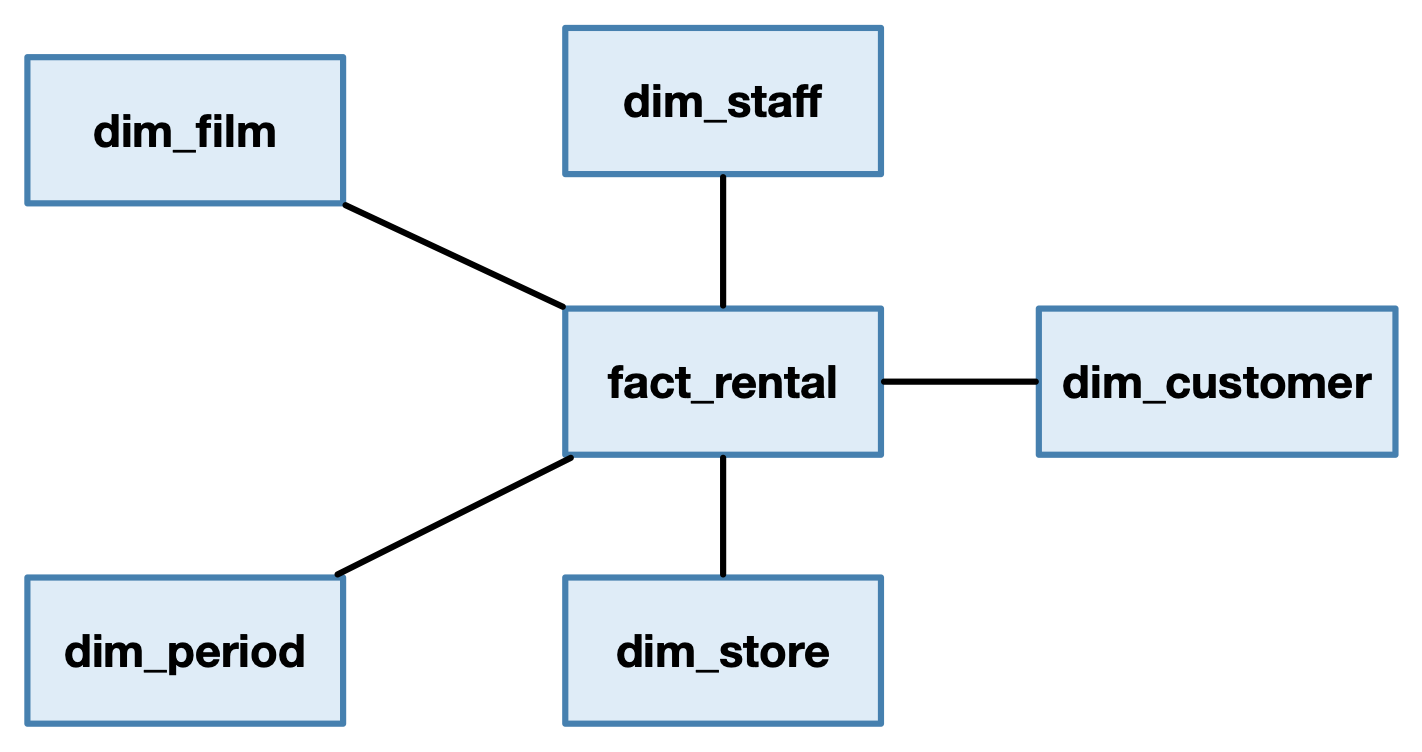
Therefore, our fact table will be fact_rental.
As for the dimensions:
Question 1. suggests the use of the dimension store (where).
Questions 2., 3. suggest the use of the dimension customer (who).
Questions 4., 5. suggest the use of the dimension staff (who).
Question 8. suggests the use of the dimension film (what).
All questions suggests the use of a time dimension (when).
The time dimension is virtually always present in a data warehouse.
Dimensional modeling
Now that we identified the fact and the dimension tables, we incrementally draw the star diagram for the Sakila data warehouse.
Exercise
Solution
Exercise
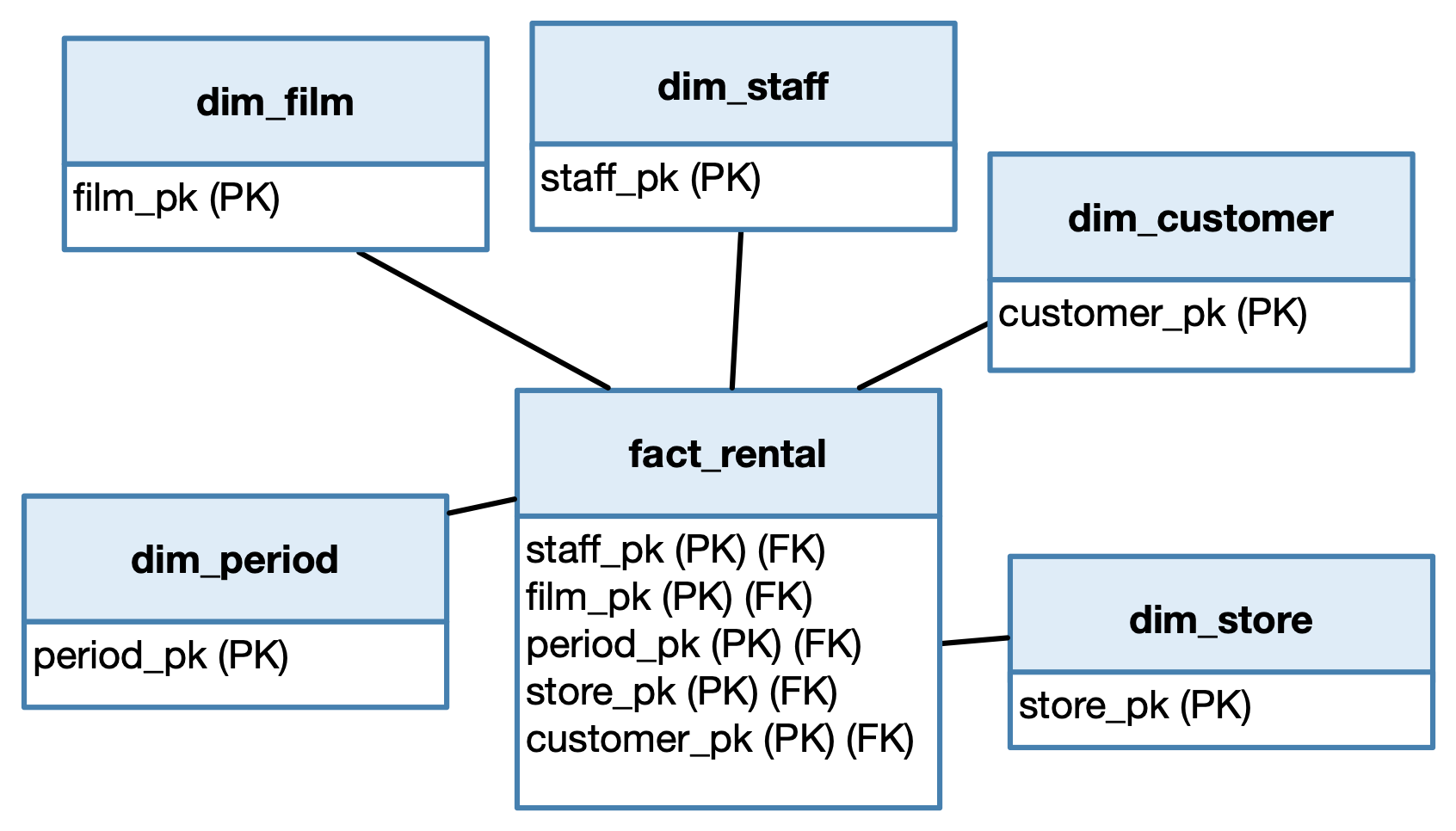
Exercise 4 Identify the primary key of the fact table.
Solution
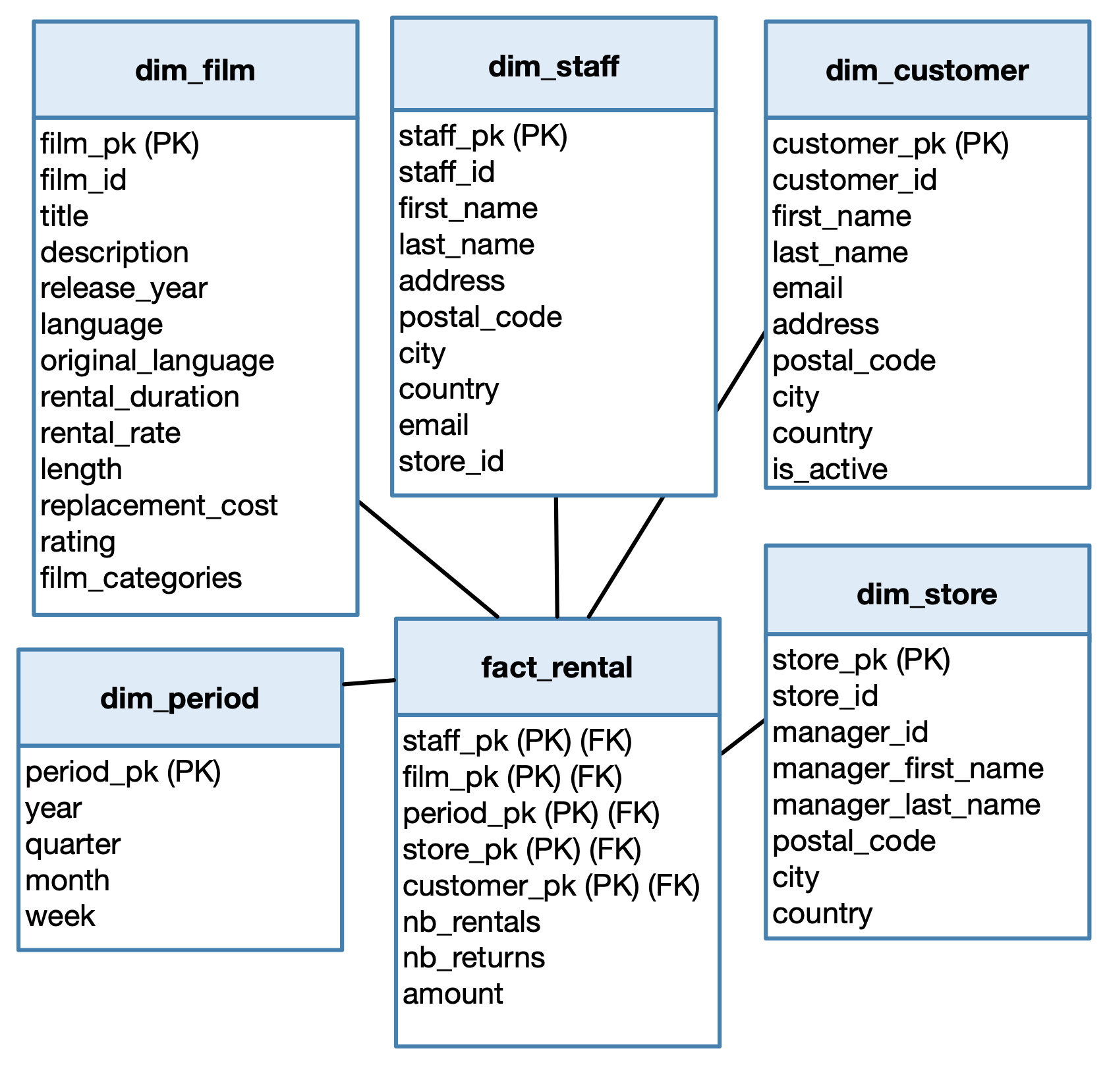
The primary key of the fact table is composed of all the attributes that refer to the dimensions. So, we write an attribute for each dimension:
staff_pk, foreign key to the dimension dim_staff.
film_pk, foreign key to the dimension dim_film.
period_pk, foreign key to the dimension dim_period.
store_pk, foreign key to the dimension dim_store.
customer_pk, foreign key to the dimension dim_customer.
Here is the new schema.
Exercise
Exercise 5 For each dimension table, there is a corresponding table in the operational database.
Discuss which attributes you would add to the dimension tables.
In particular, consider the following points:
Are you going to add to a dimension table the
primary key of the corresponding operational table?Are you going to add to a dimension table attributes that are not part of the corresponding table?
Solution
- Each dimension table already has a primary key. However, this is the surrogate key that identifies each entity in the dimension table. The business key that is in the corresponding operational table is still a valuable attribute to add.
So, for example, in the table dim_film we’ll add the attribute film_id that is the primary key in the operational table film.
- In each dimension table, we typically add all the attributes that are in the
corresponding operational table. However, we also add attributes that
are in the linked tables, if they’re necessary to our analysis.
For example, in the operational database the category of a film is
in a separate table film_category (as a result of the normalization process).
If we decide to integrate these dimensions and keep a normalized schema, we obtain a snowflake schema.
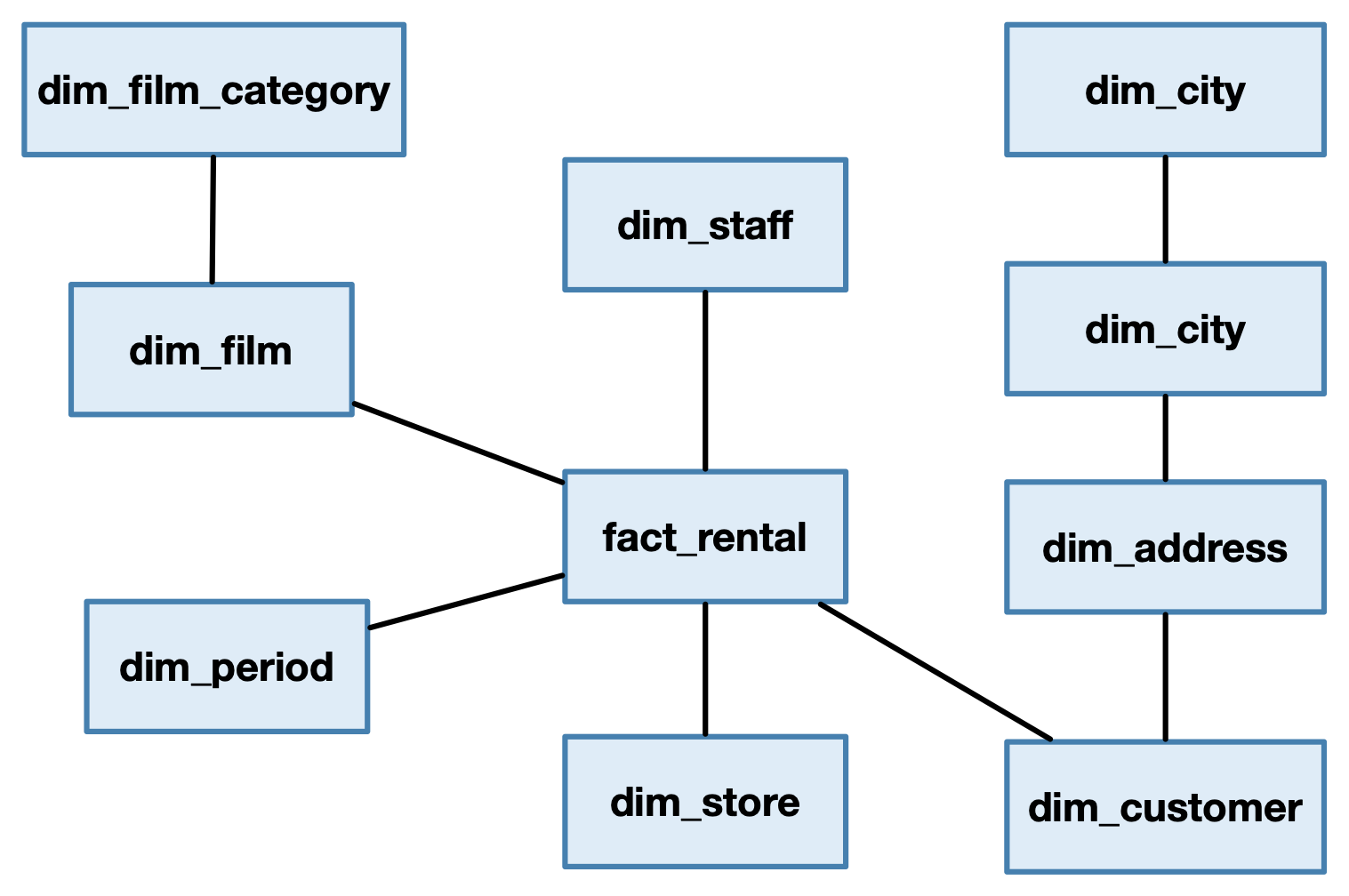
However, in a data warehouse we tend to denormalize the dimension tables, to avoid to incur the cost of joining tables.
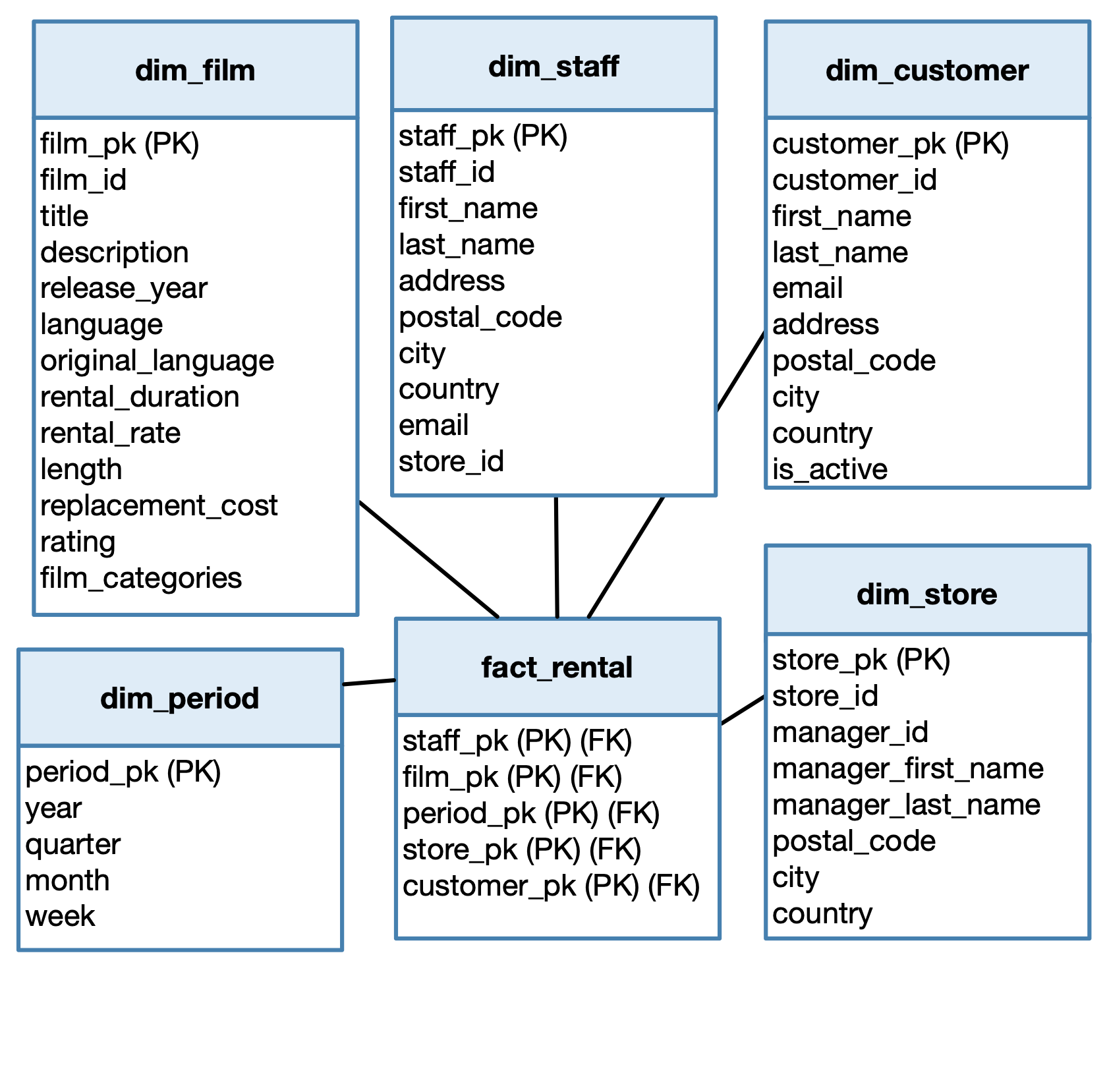
One last remark on the attribute film_categories in table dim_film. The value of this attribute is a list. One might want to avoid this by using a one-hot encoding. In other words, if the set of all possible categories is small, we can have one boolean attribute for each category; a True value would indicate that the film is in the corresponding category.
Exercise
Exercise 6 In our schema, the fact table is factless: it only contains a primary key with no measurements.
Which measurements would you introduce?
Solution
It all depends on the queries that we intend to ask. In the queries that we identified at the beginning of the tutorial, we were interested in the revenue generated by the rentals. Also, we might want to keep track of the number of rentals of a given film by a given customer in the given period, and the number of returns.