Data modeling in MongoDB
Use case scenario
The Sakila database is serving an increasing number of queries from staff and customers around the world. A single monolithic database is not sufficient anymore to serve all the requests and the company is thinking of distributing the database across several servers (horizontal scalability). However, a relational database does not handle horizontal scalability very well, due to the fact that the data is scattered across numerous tables, as are result of the normalization process. Hence, the Sakila team is turning to you to help them migrate the database from PostgreSQL to MongoDB.
For the migration to happen, it is necessary to conceive a suitable data model. From the first discussions with the Sakila management, you quickly understand that one of the main use of the database is to manage (add, update and read) rental information.
Analysis of the existing model
The existing data model is recalled in the following figure.
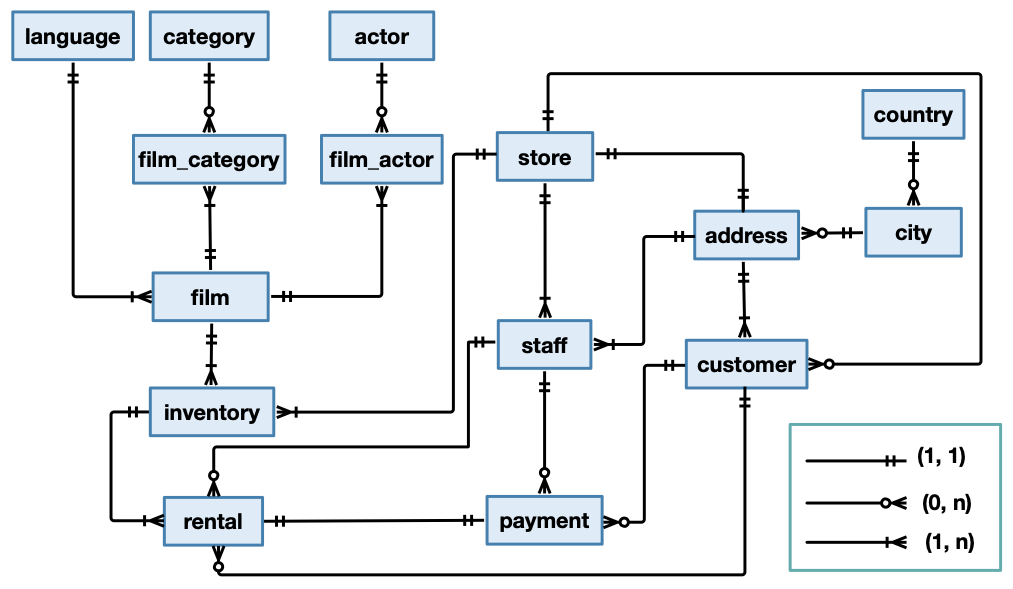
Figure 1: The conceptual schema of the Sakila database
Exercise
Exercise 1 Determine the cardinality (one-to-one, one-to-many, many-to-many) of each of the relationships in which the entity Rental is involved.
N.B. Don’t hesitate to look at the attributes of each entity in the existing PostgreSQL database.
Solution
The entity Rental has a relationship with the following tables;
Inventory. A rental refers to a single inventory (essentially, a copy of a DVD). An inventory might be part of several rentals. This is a one-to-many relationship.
Staff. A rental is taken care of by a single staff member, A staff member might take care of several rentals. This is a one-to-many relationship.
Customer. A rental is made by a single customer. A customer might make several rentals. This is a one-to-many relationship.
Payment. A payment is relative to a single rental. A rental is associated with a single payment. This is a one-to-one relationship.
Exercise
Exercise 2 Look at the tables Rental and Customer in the PostgreSQL Sakila database.
Estimate the size of a row in bytes in both tables.
The following considerations will help you in the task.
The storage size of a numeric data type is clearly indicated in the PostgreSQL documentation.
The storage size of date/time types is clearly indicated in the PostgreSQL documentation
The columns with type text hold UTF-8 characters. We assume that each character is 1 byte long (although some characters might need more than 1 byte).
The columns with type boolean needs 1 byte storage.
We assume that an email address is 25 characters long on average.
We assume that a last name is 7 characters long on average.
We assume that a first name is 6 characters long on average.
In both tables we ignore the columns last_update and create_date.
- In table Customer we ignore the column active.
Solution
For the table Rental we have:
Column rental_id, integer, 4 bytes.
Column rental_date, timestamp with time zone, 8 bytes.
Column inventory_id, integer, 4 bytes.
Column customer_id, smallint, 2 bytes.
Column return_date, timestamp with time zone, 8 bytes.
Column staff_id, smallint, 2 bytes.
In total, a row in table Rental needs 28 bytes of storage.
For the table Customer we have:
Column customer_id, integer, 4 bytes.
Column store_id, smallint, 2 bytes.
Column first_name, text, 6 bytes (average).
Column last_name, text, 7 bytes (average).
Column email, text, 25 bytes (average).
Column address_id, smallint, 2 bytes.
Column activebool, boolean, 1 byte.
In total, a row in table Customer needs 47 bytes of storage.
Considerations for the new model
We need to take some decisions as to the new data model. The considerations that we made in the previous exercises will lead us to the right decisions.
Exercise
Exercise 3
How would you model in MongoDB the entities Rental and Payment, given the cardinalities that you identified in the previous section?
Solution
The relationship between the two given entities is one-to-one. Therefore, we can use a denormalized schema in MongoDB.
That is, we can create one single collection to store the information about the two entities.
We have two options:
We create a collection Payment, where each document contains the attributes of a payment and an embedded document with the details of the rental the payment refers to.
We create a collection Rental, where each document contains the attributes of a rental and an embedded document with the details of the payment for the rental.
Although both options are perfectly valid, we prefer the second one, as rentals are our first-class citizens in our database.
We can also consider the attributes of a payment as attributes of a rental, without creating an embedded document for the payment.
Exercise
Exercise 4 Suppose that we create a collection Customer and we embed in each customer document the list of rentals for that customer.
How many rentals can we store at most for a given customer, knowing that the size of a document cannot exceed 16 MB?
Solution
We’ve seen before that each rental needs 28 bytes of space. To make the computation easier, we round this size up to 32 bytes (a power of two). Considering that 16 MB = \(16 \times 2^{20}\), the maximum number of rentals that we can store for a given customer is given by:
\[ \frac{16 \times 2^{20}}{32} = 2^{-1} \times 2^{20} = 2^{19} \]
This gives around 600,000 rentals.
Exercise
Exercise 5 In our current database we have:
599 customers.
16044 rentals.
On average, each customer has around 27 rentals.
Compute the size in byte of the two following collections:
Collection Customer, where each document contains the information about a customer and an embedded list with the information on all the rentals made by the customer.
- Collection Rental, where each document contains the information about a rental and an embedded document with the information on the customer that made the rental.
Solution
We previously found out that for each customer we need 47 bytes and for each rental we need 28 bytes.
A document that holds the data about a customer and the list of all the rentals of the customer will need \(47 + 27 \times 28 = 830\) bytes.
Hence, the total size of the Customer collection is \(803 \times 599 = 480977\) bytes, that is 470 KB.
A document that holds the data about a rental and its customer needs $ 28 + 47 = 75 $ bytes.
Hence, the total size of the Rental collection is \(75 \times 16044 = 1203300\) bytes, that is 1,1 MB.
Exercise
Exercise 6 Discuss advantages and disadvantages of the two following options:
A collection Customer with a document for each customer holding the list of all the rentals of the customer.
- A collection Rental with a document for each rental holding the data on the relative customer.
Solution
Advantages of solution 1.:
There is no redundancy. In fact, a rental is relative to at most one customer, therefore the data on a rental is not duplicated across different documents.
As a result, the size of the collection is smaller than the collection in solution 2.
For each customer, we retrieve the information on all his/her rentals with only one read operation
Disadvantages of solution 1.:
There is a limit (albeit an acceptable one) on the number of rentals that we can store for each customer.
We lose a “rental-centric” view of our data. As a result, if any other document in another collection (e.g., staff) refers to a rental, all the information about a rental must be denormalized in that document.
Advantages of solution 2.
A “rental-centric” view of our data. Aggregating information from different rentals does not require digging rentals out of several lists.
The size of each document is small and will never exceed the 16 MB limit.
As a result, reading a document from the collection takes less time and memory than reading a document from the collection in solution 1.
Disadvantages of solution 2.
There is a lot of redundancy. The information about a customer are replicated each time the customer makes a rental.
As a result, the size of the collection is much higher than in solution 1.
It seems that one of the two solutions has a higher storage demands than the other, and therefore the odds seems to be stacked against that solution.
However….
We still have to consider two more entities that are linked to the rentals: staff and inventory.
Exercise
Exercise 7 Discuss how you can fit staff and inventory in each of the solutions presented in the previous exercise. Discuss advantages and disadvantages of each option that you present.
Solution
Solution 1
We need to somehow link staff and inventory to the relative rental. We have three options:
We embed staff and inventory into each rental document, which, let’s recall it, is already embedded in an array. This creates redundancy, as a staff member or an inventory item can appear in more than one rental.
We create three separate collections (Customer, Staff and Inventory) and in each we embed an array with the list of the relative rentals. The problem is that the data on the rentals are now replicated three times. This solution is particularly bad, because rentals are frequently written. When we create a rental, we need to write three documents; when a customer returns an item, we need to update the return date in three documents.
We create four collections (Customer, Staff, Inventory and Rentals); for each customer, staff and inventory we keep a list of rentals, each item being the identifier that refers to the appropriate rental. We fall back to the normalized schema of the PostgreSQL database. Then, it isn’t clear how this normalized schema will help horizontally scale the database.
Solution 2
We have only one collection Rental; in each document, we have an attribute customer, whose value is an embedded document with all the information about a customer, an attribute staff, whose value is an embedded document with all information about a staff member, and an attribute inventory, whose value is an embedded document with all information about an inventory item.
This solution has higher storage requirements than the options presented in solution 1, but it has the clear advantage of being a denormalized schema, where we control every facet of a rental (customer, staff, inventory). Moreover, when we create a rental, we only write one document ; when we update the return date of a rental, we only update one document.
From the previous exercise, we have a clearer idea as to the best solution to our case. We take a closer look at the storage requirements of the adopted solution. Consider that:
The size in byte of a document storing the information of a staff member is around 84000 bytes (we also store a profile picture).
The size in byte of a document storing the information of an inventory item is 16 bytes.
Exercise
Exercise 8 If we denote by \(N_{rental}\) the number of rentals, what is the size in bytes of the whole database for the adopted solution?
Solution
Let’s recall that the size in bytes of a document storing the information on a customer is 47 bytes.
The size of the only collection Rental (hence, of the whole database) is:
\[ N_{rentals} \times (47 + 84000 + 16) = N_{rentals} \times 84063 \]
With 10,000 rentals, the size of the database is 800 MB. With 100,000 rentals, the size of the database is 7 GB. With 1,000,000 rentals, the size of the database is 78 GB.
Although the size that we determined in the previous exercise, may not sound impressive, we still have to store other information (films, actors….). If we could save a bit of space, we would be happy.
Exercise
Exercise 9 Discuss how you could save some space in the adopted solution.
HINT. Do you really need to denormalize all data?
Solution
While modeling data for a MongoDB database, the choice between a normalized and a denormalized schema does not need to be a black and white one.
We can have a denormalized schema, where we embed in the same documents information that are queried together, while storing in a separate collection the information that are rarely queried.
For instance, the profile picture of a staff member might not be an important piece of information while we’re trying to analyze which staff members are the more productive ones.
So, we might add another collection Staff where each document only contains attributes that are not in embedded documents in the collection Rental.
Exercise
Exercise 10 Propose a solution for all the entities involved and estimate the saving in terms of storage requirements.
Solution
Here is a solution with three different collections. The information on inventory are completely denormalized into the collection Rental. For customers and staff members we only keep the necessary information and we normalize the information that are less likely to be queried while analyzing the rentals.
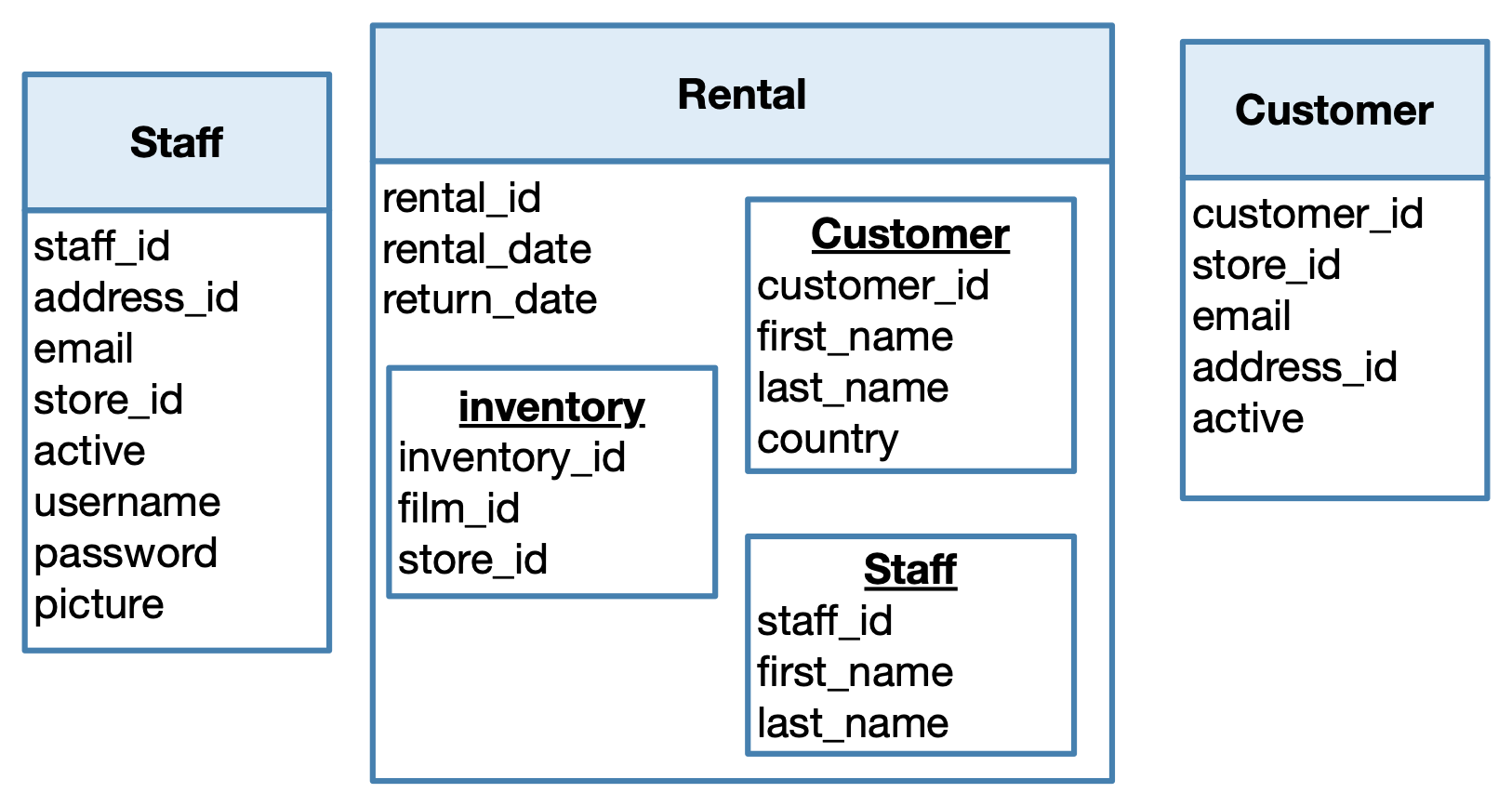
Let’s try to estimate the savings in terms of storage. In a document of the collection Rental, we have the following attributes:
rental_id: 4 bytes.
rental_date and return_date: 16 bytes.
inventory_id: 4 bytes
film_id and store_id: 4 bytes
customer_id: 4 bytes
customer first and last names: 13 bytes.
country: 9 bytes (on average a country name has 9 characters).
staff_id: 4 bytes
staff first and last name: 13 bytes.
In total a document in our collection Rental will have 71 bytes (a huge improvement wrt the 84000 bytes of our first solution).
Of course, the size of a document in the Staff collection will be around 84000 bytes (we still store the profile picture). However, the number of staff members \(N_{staff}\) is much lower than the number of rentals \(N_{rentals}\).
It is easy to verify that the size of a document of the collection Customer is 34 bytes (same information as before except first and last name). Again, the number of customers \(N_{customers}\) is much lower than \(N_{rentals}\).
We assume that each customer has on average 30 rentals and for 100 customers we have 1 staff member. We have that:
$N_{customer} = N_{rental}/30 $
$N_{staff} = N_{customer}/100 = N_{rental}/3000 $
So, the size of the database will be given by:
\[ 71\times N_{rentals} + 84000 \times N_{rentals}/3000 + 34 \times N_{rentals}/30 = 100 \times N_{rental} \]
If we want to compare against the first solution:
- With 10,000 rentals, the size of the database is 976 KB (instead of 800 MB). With 100,000 rentals, the size of the database is 9,5 MB (instead of 7 GB). With 1,000,000 rentals, the size of the database is 95 MB (instead of 78 GB).
As you can see, a big improvement! And we have a denormalized schema that lets us take advantage of the horizontal scalability of MongoDB.
The new model
In this section we intend to obtain a complete model of the Sakila database.
Exercise
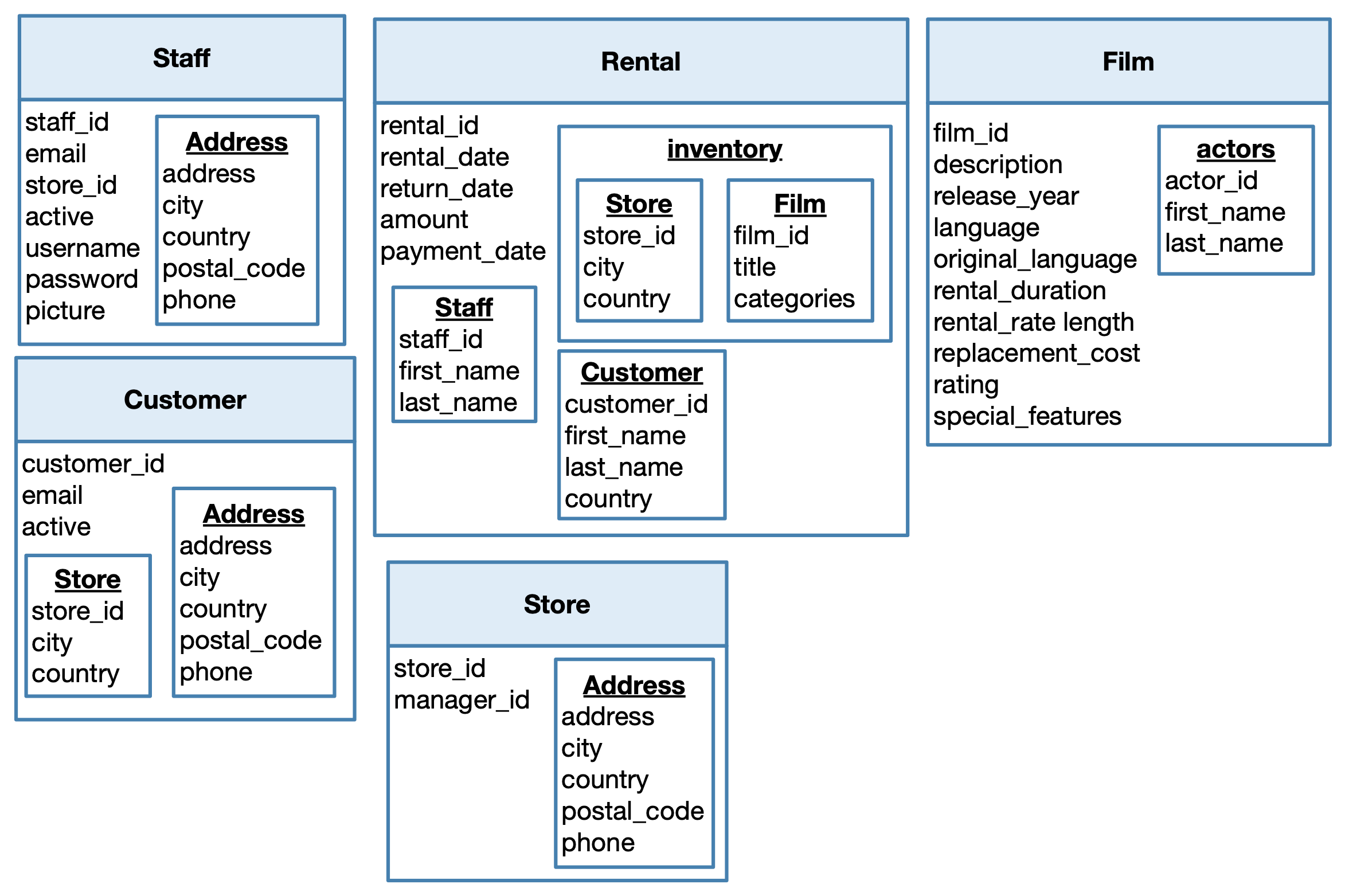
Exercise 11 Consider the model that we obtained at the end of the previous section. Which data can you further denormalize?
Solution
Collection Staff
The attribute address_id refers to a full address. We can fully denormalize this information into the documents of the collection.
The attribute store_id refers to the store where the staff member works. The Store table in the original PostgreSQL database does not have too many columns. Therefore, it might be reasonable to fully denormalize these data. However, information on the stores are also linked to customers and to inventory items. If we need to update, say, the manager of a store, we would need to update three different documents. Hence, we prefer to create a collection Store and keep in the documents of the collection Staff only the city and country of a store (and its identifier of course).
Attribute Inventory in collection Customer
Same considerations for the attribute store_id.
The attribute film_id is the reference to the film the inventory item is relative to. The table Film in the original PostgreSQL database contains 14 columns. This high number of attributes advises us against a full denormalization, considering that a film can be relative to multiple inventory items. We might only keep the film title and the film categories. The rest of the attributes are kept in documents of a separate collection Film.
Collection Customer
Same considerations for the attributes store_id and address_id.
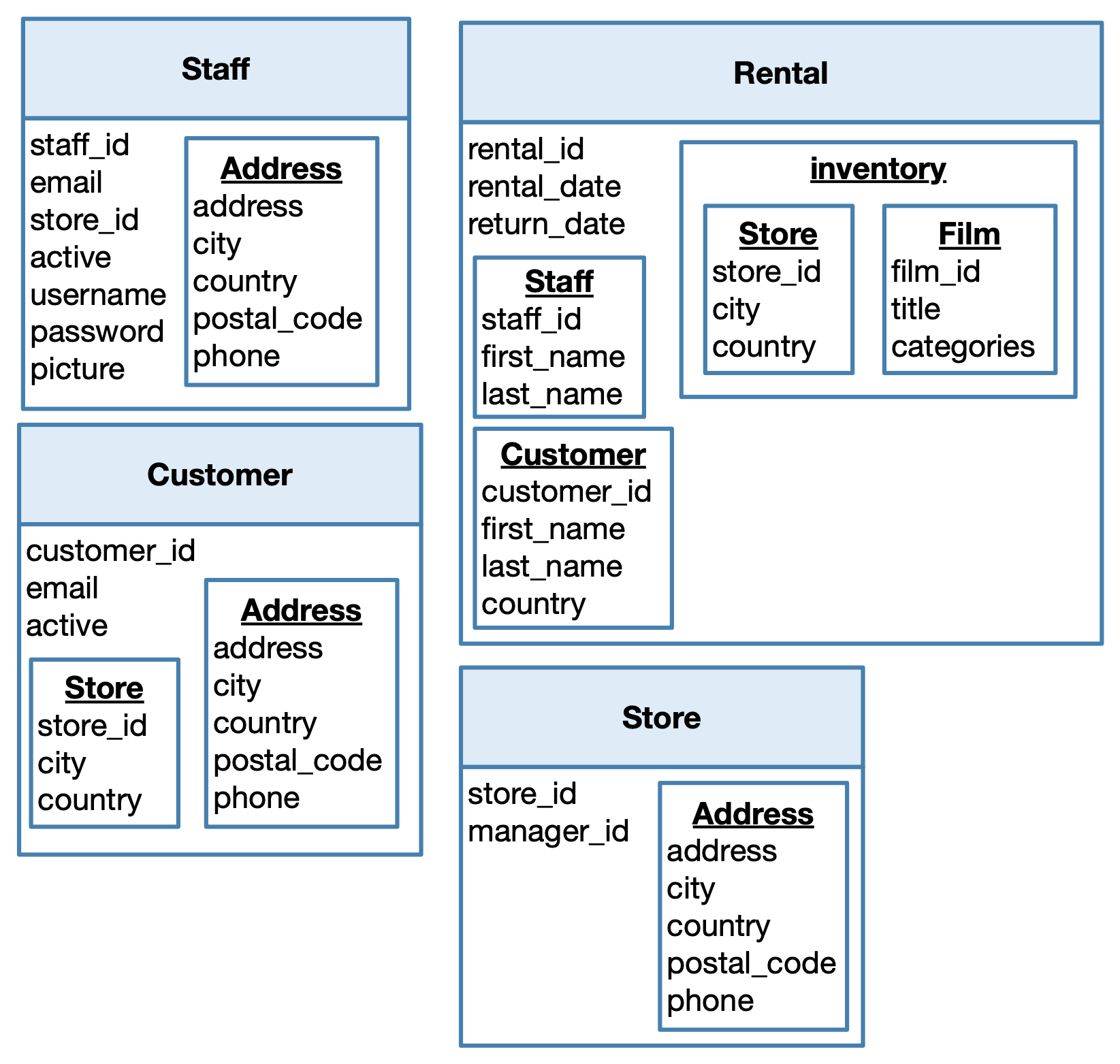
Exercise
Exercise 12 Complete the diagram obtained in the previous exercise so as to obtain a full data model for the Sakila database.
Solution