Neo4j
Setting up the work environment.
Download Neo4j Desktop and install it on your computer.
Create a new project by clicking on the button “New” that you’ll find on the top left side of the window.
Click on “Add Database”, then “Create a Local Database”.
Give the database a name (e.g., MovieLens) and set a password that you can easily remember; then click on “Create”. Choose version 4.4.8 for the database.
Click on “Start” and wait for the database to become active.
Click on the button “Open”. The Neo4j Browser will pop up.
In the next section, you’ll have to type a sequence of commands to import the data. You’ll write the commands in the text field on top of the Neo4j Browser (where you find the prompt neo4j$).
Import the data.
The dataset consists of data obtained from MovieLens, a recommender system whose users give movies a rate between 1 and 5, based on whether they dislike or love them. MovieLens uses the rates to recommend movies that its users might like. The dataset is modeled as a directed graph and consists of 100,004 rates on 9,125 movies across 671 users between January 9th, 1995 and October 16, 2016. The dataset also contains the names of the directors and the actors of each movie.
- Import the nodes corresponding to the movies (label Movie) by using the following command (it took 31 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/movies.csv' as row
MERGE (m:Movie {movie_id: toInteger(row.movie_id), title_en:row.movie_title_en, title_fr:row.movie_title_fr, year: toInteger(row.movie_year)})
RETURN count(m)
- Create an index on the property movie_id of the nodes with label Movie with the following command:
create index movie_idx for (m:Movie) on (m.movie_id)
- Import the nodes corresponding to the actors (label Actor) by using the following command (it took 62 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/actors.csv' as row
MERGE (a:Actor {actor_id: toInteger(row.actor_id), name:row.actor_name})
RETURN count(a)
- Create an index on the property actor_id of the nodes with label Actor with the following command:
create index actor_idx for (a:Actor) on (a.actor_id)
- Import the nodes corresponding to the directors (label Director) by using the following command (it took 4 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/directors.csv' as row
MERGE (d:Director {director_id: toInteger(row.director_id), name:row.director_name})
RETURN count(d)
- Create an index on the property director_id of the nodes with label Director with the following command:
create index director_idx for (d:Director) on (d.director_id)
- Import the nodes corresponding to the genres (label Genre) by using the following command (it took 197 ms on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/genres.csv' as row
MERGE (g:Genre {genre_id: toInteger(row.genre_id), name:row.genre_name})
RETURN count(g)
- Create an index on the property genre_id of the nodes with label Genre with the following command:
create index genre_idx for (g:Genre) on (g.genre_id)
- Import the nodes corresponding to the users (label User) by using the following command (it took 347 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/users.csv' as row
MERGE (u:User {user_id: toInteger(row.user_id), name:row.user_nickname})
RETURN count(u)
- Create an index on the property user_id of the nodes with label User with the following command:
create index user_idx for (u:User) on (u.user_id)
- Import the links of type ACTED_IN between actors and movies with the following command (it took 2.5 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/movies_actors.csv' as row
MATCH (m:Movie {movie_id: toInteger(row.movie_id)})
MATCH (a:Actor {actor_id: toInteger(row.actor_id)})
MERGE (a)-[r:ACTED_IN]->(m)
RETURN count(r)
- Import the links of type DIRECTED between directors and movies with the following command (it took 688 ms on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/movies_directors.csv' as row
MATCH (m:Movie {movie_id: toInteger(row.movie_id)})
MATCH (d:Director {director_id: toInteger(row.director_id)})
MERGE (d)-[r:DIRECTED]->(m)
RETURN count(r)
- Import the links of type HAS_GENRE between movies and genres with the following command (it took 1 second on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/movies_genres.csv' as row
MATCH (m:Movie {movie_id: toInteger(row.movie_id)})
MATCH (g:Genre {genre_id: toInteger(row.genre_id)})
MERGE (m)-[r:HAS_GENRE]->(g)
RETURN count(r)
- Import the links of type RATED between users and movies with the following command (it took 5.9 seconds on my computer):
:auto USING PERIODIC COMMIT 1000
LOAD CSV WITH HEADERS FROM 'https://gquercini.github.io/courses/plp/tutorials/neo4j/user_rates.csv' as row
MATCH (m:Movie {movie_id: toInteger(row.movie_id)})
MATCH (u:User {user_id: toInteger(row.user_id)})
MERGE (u)-[r:RATED {rate:toFloat(row.rate)}]->(m)
RETURN count(r)
Exploratory queries
If you looked at the commands used to import the data, you might already have an idea as to the structure of the graph. You can get a glimpse on the node labels, the relationship types and the property keys by clicking on the button circled in the following figure:

Exercise 1 Write and execute the following query:
MATCH (m:Movie {title_en:"Toy Story"})
RETURN m;
What do you obtain? What are the properties associated to a node with label Movie? Click once on the node to display its properties.
Solution
The requested node is displayed in the Neo4j Browser. By clicking on the node, we see that the properties are: movie_id, title_en, title_fr, year.
Exercise 2 Double-click on the node displayed as the result of the previous query. Analyze the neighbouring nodes (their labels and properties) and the incident links (direction, type and properties). You can move around the node by dragging it in the window.
Solution
From the interface, we see that the movie Toy Story is rated by 90 users, has 5 genres, 4 actors and 1 director. The following observations can be made:
Each node with label User has two properties, user_id and name.
Each node with label Genre has two properties, genre_id and name.
Each node with label Director has two properties, director_id and name.
Each node with label Actor has two properties, actor_id and name.
A relationship of type RATED has a property rate and is directed from a node with label User to a node with label Movie.
A relationship of type DIRECTED is directed from a node with label Director to a node with label Movie.
A relationship of type HAS_GENRE is directed from a node with label Movie to a node with label Genre.
A relationship of type ACTED_IN is directed from a node with label Actor to a node with label Movie.
Queries
Exercise 3 Write and execute the following queries:
Q1. The genres of the movies in the database.
Q2. The number of movies in the database.
Q3. The title of the movies released in 2015.
Q4. The number of directors by movie. Sort in decreasing order.
Q5. The names of the directors and the title of the movies that they directed and in which they also played.
Q6. The genres of the movies in which Tom Hanks played.
Q7. The title and the rate of all the movies that the user with identifier 3 rated. Sort by rate in decreasing order.Solution
MATCH (g:Genre) RETURN g.nameQ2.
MATCH (n:Movie) RETURN count(n)Q3.
MATCH (n:Movie {year:2015})
RETURN n.title_en;
Q4.
MATCH (n:Movie)<-[:DIRECTED]-(d:Director) RETURN n.title_en, count(*) AS nb_directors ORDER BY nb_directors DESCQ5.
MATCH (a:Actor)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Director) WHERE a.name=d.name RETURN a.name, m.title_en;Q6.
MATCH (:Actor {name:"Tom Hanks"})-[:ACTED_IN]->(:Movie)-[:HAS_GENRE]->(g:Genre)
RETURN DISTINCT (g.name);
Q7.
MATCH (n:User {user_id:3})-[r:RATED]->(m:Movie)
RETURN m.title_en, r.rate
ORDER BY r.rate desc;
Query chaining
Cypher allows the specification of complex queries composed of several queries that are concatenated with the clause WITH. We are now going to see an example to obtain the titles of the movies that have been rated by at least 100 users.
At a first glance, the following query looks like a good solution:
MATCH (n:Movie)<-[:RATED]-(u:User) WHERE count(u) >= 100 RETURN n.title_en LIMIT 5;
However, executing this query returns the following error:
Invalid use of aggregating function count(...) in this context (line 1, column 42 (offset: 41)) "MATCH (n:Movie)<-[:RATED]-(u:User) WHERE count(u) >= 100"
Similarly to SQL, we cannot use aggregating functions in the clause WHERE.
A correct formulation of the query requires the use of the clause WITH to concatenate two queries: the first will count the number of rates for each movie:
MATCH (n:Movie)<-[:RATED]-(u:User) RETURN n, count(u) as nb_rates
The second will take in the output of the first and will filter all the movies where nb_rates < 100. In order to chain the two queries, we’ll replace the RETURN clause in the first query with a WITH clause, as follows:
MATCH (n:Movie)<-[:RATED]-(u:User) WITH n, count(u) as nb_rates WHERE nb_rates >= 100 RETURN n.title_en
Exercise 4 Write and execute a query to obtain the five movies that obtained the best average rate among the movies that have been rated by at least 100 users.
Solution
MATCH (n:Movie)<-[r:RATED]-(u:User) WITH n, avg(r.rate) as avg, count(u) AS nb_rates WHERE nb_rates >= 100 RETURN n.title_en, avg ORDER BY avg DESC;
Movie recommendation
We are now going to see how Neo4j can be effectively used in a real application by implementing queries that form the basis of a simple movie recommendation system. This system is based on the notion of collaborative filtering.
This consists in recommending a user \(u\) some films that s/he hasn’t rated yet and other users with similar preferences have loved. In our context, we say that a user loves a movie if s/he rated the movie at least 3.
This concept is explained in the following figure.
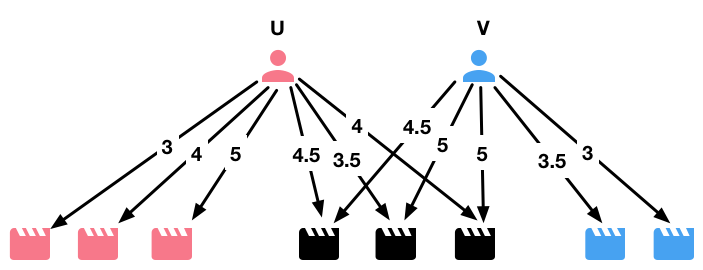
The user \(u\) loves 6 movies, 3 of which are also loved by the user \(v\) (the black nodes); it is reasonable to think that \(u\) may also love the two movies that \(v\) loved and \(u\) hasn’t rated yet.
The principle of collaborative filtering is based on the computation of a similarity score between two users. Several similarity scores are possible in this context; here, we are going to use the Jaccard coefficient. Let \(L(u)\) and \(L(v)\) be the sets of movies that \(u\) and \(v\) love respectively; the similarity score \(J(u,v)\) between \(u\) and \(v\) is given by:
\[ J(u, v) = \frac{|L(u) \cap L(v)|}{|L(u) \cup L(v)|} \]
In order to recommend movies to a target user \(v\), the recommender system computes the similarity score between \(v\) and all the other users of the system and proposes to \(v\) the movies that s/he hasn’t rated yet and that the \(k\) most similar users loved.
We are now going to incrementally write a query to recommend some movies to the target user 3. The first step consists in determining the value \(|L(v)|\).
Exercise 5 Write and execute the query to obtain the number of movies that the user 3 loved. This query must return the target user and the number of movies that s/he loves.
Solution
MATCH (target:User {user_id:3})-[r:RATED]->(m:Movie)
WHERE r.rate >= 3
RETURN target, count(m) AS lovedByTarget;
Next, we are going to determine the value \(|L(u)|\), for all users \(u\) except \(v\).
Exercise 6 Write and execute the query to obtain the number of movies that each user \(u\) loves, except the target user 3. This query must return each user \(u\) and the number of movies that s/he loves.
Solution
MATCH (other:User)-[r:RATED]->(m:Movie) WHERE other.user_id <> 3 and r.rate >= 3 RETURN other, count(m) as lovedByOther
We put the two queries together with the clause WITH.
Exercise 7 Compose the two previous queries with the clause WITH. This query must return the target user 3, the number of movies that s/he loves, the other users \(u\) and the number of movies that they love.
Solution
MATCH (target:User {user_id:3})-[r:RATED]->(m:Movie)
WHERE r.rate >= 3
WITH target, count(m) AS lovedByTarget
MATCH (other:User)-[r:RATED]->(m:Movie)
WHERE other <> target and r.rate >= 3
RETURN target, lovedByTarget, other, count(m) as lovedByOther
Now, we need to determine the value \(L(u)\cup L(v)\), for each user \(u\), and compute the similarity score with the Jaccard coefficient.
Exercise 8 Append (by using WITH) to the query written in the previous exercise a query that obtains the number of movies that any user \(u\) loved and that the target user 3 loved too, and computes the similarity score between the target user 3 and \(u\). This query must return the five most similar users to the target user and the similarity scores.
Hint
Multiply the numerator of the equation by 1.0, otherwise Cypher will compute an integer division.Solution
The following is the query written at the previous exercise, where the RETURN clause has been replaced with WITH.
MATCH (target:User {user_id:3})-[r:RATED]->(m:Movie)
WHERE r.rate >= 3
WITH target, count(m) AS lovedByTarget
MATCH (other:User)-[r:RATED]->(m:Movie)
WHERE other <> target and r.rate >= 3
WITH target, lovedByTarget, other, count(m) as lovedByOther
We have to append the following query:
MATCH (target)-[r:RATED]->(m:Movie)<-[r1:RATED]-(other) WHERE r.rate >= 3 and r1.rate >= 3 RETURN other, count(m)*1.0 / (lovedByTarget + lovedByOther - count(m)) as sim ORDER BY sim DESC LIMIT 5
The last step consists in recommending some movies to the target user. From the previous query, take the identifier of the user \(w\) with the highest similarity to the target user. You are going to use this identifier directly in the new query.
Exercise 9 Write and execute the query to obtain the list of the movies that the user \(w\) loved and that the target user hasn’t rated yet. Sort this list by decreasing rate.
Hint
- First, write a query to obtain the list of the movies that the target user rated. In the MATCH clause, use the variable \(m\) to indicate a movie that the target user rated. Conclude the query with:
RETURN collect(m.title_en) AS movies
The function collect creates a list called movies.
- Replace RETURN with WITH in the previous query and add a second query to select the titles of the movies \(m\) that the user \(w\) loved and the target user did not rate. In order to exclude the films that the target user did not rate, use the following predicate:
none(x in movies where x=m.title_en)
in the WHERE clause.
Solution
The following is the query written at the previous exercise, where the RETURN clause has been replaced with WITH.
MATCH (target:User {user_id:3})-[r:RATED]->(m:Movie)
WITH collect(m.title_en) as movies
MATCH (u:User {user_id:129})-[r:RATED]->(m:Movie)
WHERE r.rate >=3 AND none(x IN movies WHERE x=m.title_en)
RETURN m.title_en
ORDER BY r.rate DESC;